2
Analyzing learning curves is one of the fundamental skills you should build in your career. There are different learning curves, but we will focus on Abigail’s chart.
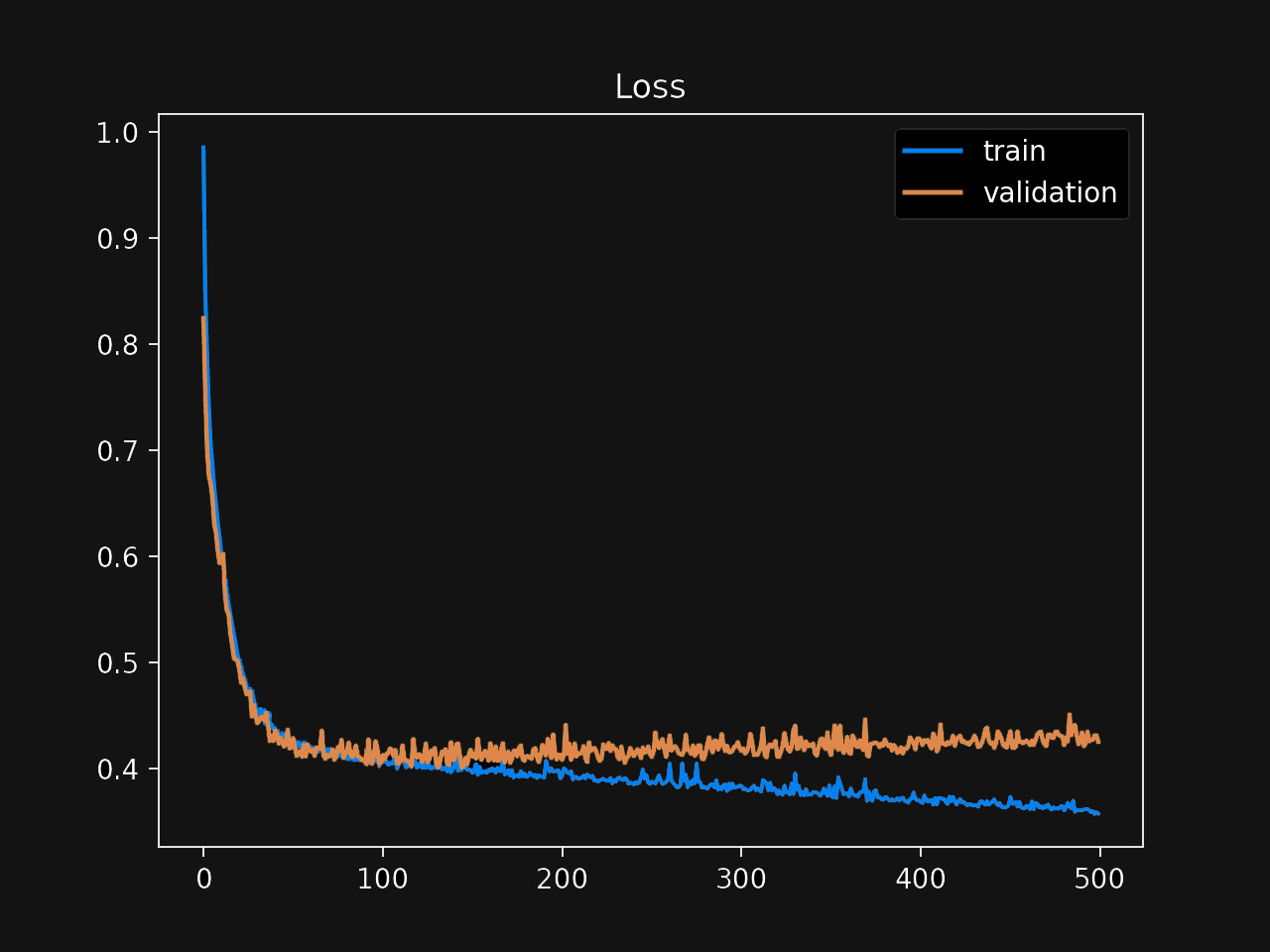
First, notice that the chart shows the loss—or error—as we increase the number of training iterations. A good mental model is to look at this the following way: “as we keep training, how much better the model gets?” Since we are displaying the loss, larger values are worse, so having both lines decrease is a good sign.
We have two lines in the chart: one representing the loss we get during training, the other representing the loss during the validation process. How these lines look concerning each other is essential. Most of the time, one of the lines alone wouldn’t give you a complete picture of the situation.
Let’s start with the first choice that argues that a training loss that’s continually decreasing is good. Indeed this could be a good sign in isolation: the more we train our model, the fewer mistakes we make on the training dataset, but this is not enough to draw any conclusions.
Always be suspicious of an always-decreasing training loss; it’s a sign that your model might be memorizing the data. Usually, you want a model that learns up to a point, and then the loss stays flat. But how do you know when during the process that should happen? The relationship between the training loss and the validation loss shows how they start diverging at about 100 iterations. This point is the key.
Think about it this way: Abigail’s model “continues learning” the training data but stops learning the validation data at about 100 iterations. The model is overfitting: it’s memorizing the training data, which is not helping with the validation data. Therefore, the first choice is incorrect, and the second is correct.
The third choice is incorrect as well. You’ll always see a similar slow down in the loss functions. The best case—not usual, but technically possible—is to reach 0, where there’s nowhere else to go.
Finally, the fourth choice is also incorrect. First, the training and validation loss do not necessarily need to follow each other. Second, this model shows overfitting—memorizing the training data—and not underfitting—lack of model complexity to learn the data correctly. You can usually identify an underfitting model when its training loss is flat or doesn’t decrease much.
In summary, the second choice is the correct answer to this question.
Recommended reading