Two experiments. Round one.
Lena ran two experiments training a neural network on a sample dataset. Her goal is to understand how different batch sizes affect the training process.
One of the experiments used a very small batch size, and the other used a batch size equal to all existing training data.
After training and evaluating her models, Lena plotted the training and testing losses over 100 epochs of one of the experiments, and this is what she got:
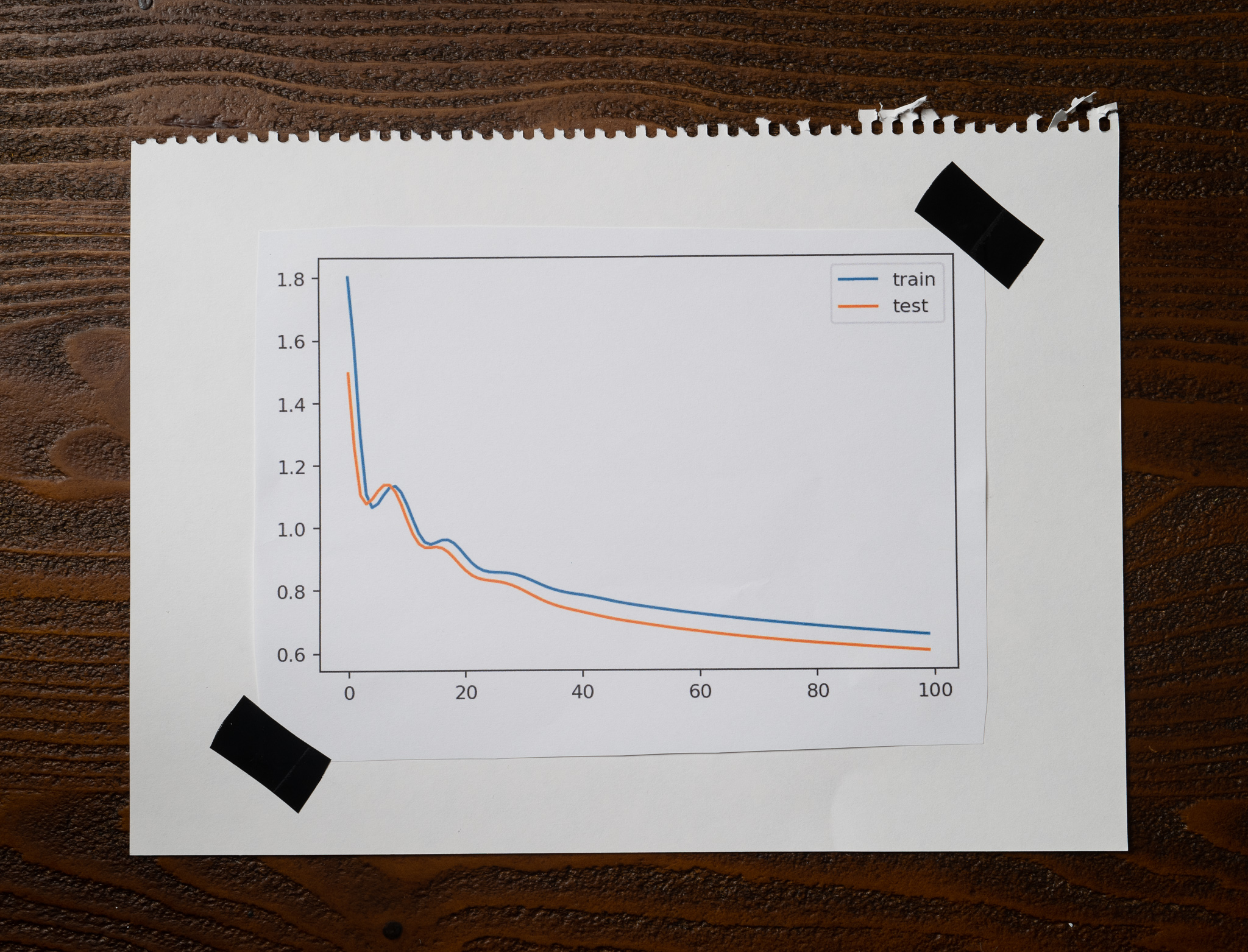
Which of the following options is the most likely to be true?
The model behind this plot corresponds to the experiment that used a very small batch size. This model was the one that took less time to train.
The model behind this plot corresponds to the experiment that used a very small batch size. This model was the one that took longer to train.
The model behind this plot corresponds to the experiment that used a batch size equal to all the available training data. This model was the one that took less time to train.
The model behind this plot corresponds to the experiment that used a batch size equal to all the available training data. This model was the one that took longer to train.