Yeah, I’m not a huge fan of math, either.
But to make a career in machine learning, you need at least to know some of the underpinnings behind specific techniques.
Let’s pick neural networks, for example. The whole idea of optimizing the network rests on understanding how to compute the gradient of a function.
Which of the following is true about the gradient of a continuous and differentiable function?
The gradient of a continuous and differentiable function is zero at a minimum value.
The gradient of a continuous and differentiable function is zero at a saddle point.
The gradient of a continuous and differentiable function is non-zero at a maximum value.
The gradient of a continuous and differentiable function decreases as it gets closer to a minimum value.
1, 2
To keep it simple, the gradient of a function gives us the slope at any point on its curve. We can compute it by dividing the “rise” of the function by its “run” over a specific small interval.
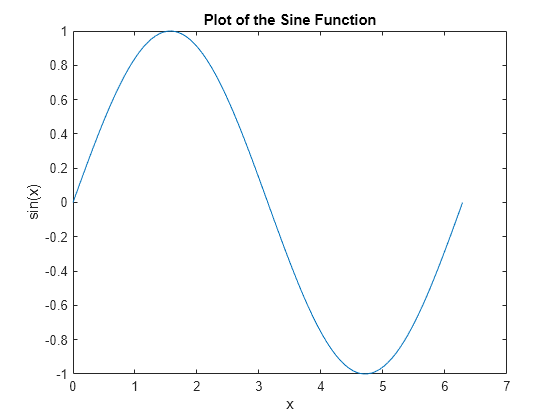
Imagine the Sine function. Pick a point on the left side, and think of the tangent to the curve as you move the point closer to the maximum value of the function. The gradient starts positive and decreases as we get closer to the maximum.
Repeat this exercise, starting from the maximum value and moving towards the minimum. The gradient is negative after the maximum point and increases until it reaches the minimum value. Visualizing this in your head is not easy, so here is an excellent interactive chart where you can see how this works using a similar function.
What happens with the gradient when we get to a minimum, maximum, or saddle point? The gradient will equal zero if the curve has a horizontal slope at a particular point. That means that both the first and second choices correctly describe the properties of the gradient function. However, the third choice is invalid: we already know that the gradient function is zero when we hit a maximum point.
Recommended reading
{kind=link}